布隆过滤器(Bloom Filter)在实际的项目中有广泛的应用:
一、原理
布隆过滤器[1]本质上是一个二进制向量[2],在程序中使用数组来表示向量。
对于布隆过滤器,应该支持一下的方法:
- 初始化(Init)
- 添加元素(Add)
- 判断元素是否存在(is Exist)
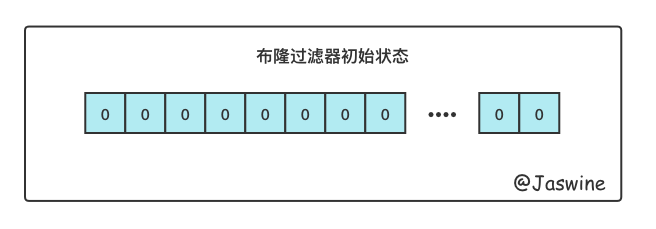
1.1.初始化
当执行初始化的时候,创建一个数组,并且数组中每个值都是0。这里会遇到一个问题,这个数组需要申请多大?这里先按下不表。初始化之后,布隆过滤器如下图所示。
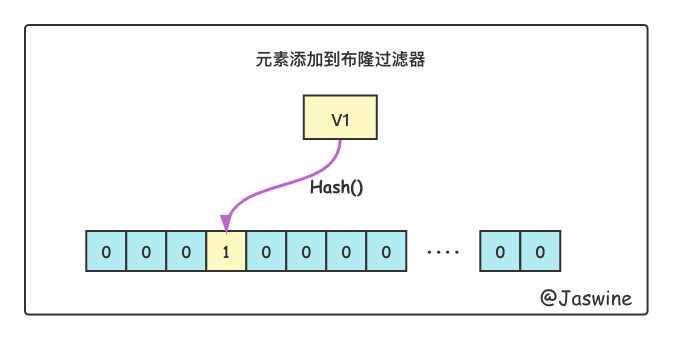
1.2.添加元素
将一个值添加到布隆过滤器中,先对这个值进行hash[3]计算,得到一个数组下标,将数组中的这个值修改成为"1"。这个值就放到了布隆过滤器中。这个过程如下图所示:
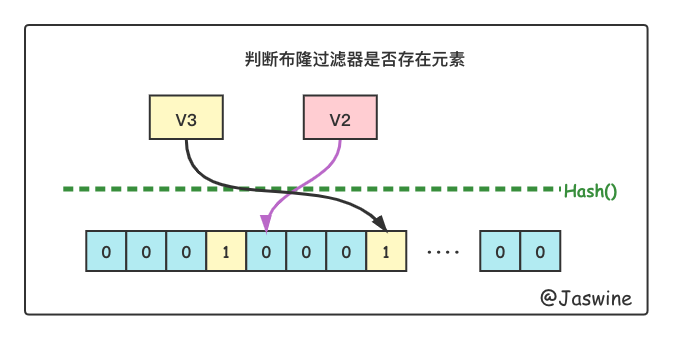
1.3.判断是否存在某个元素
判断布隆过滤器中是否含有一个元素,就是将这个值经过hash计算后,判断对应下标的数组的值。如果值为"0",那么这个元素一定不在布隆过滤器中,如果值为"1",那么布隆过滤器中可能存在这个元素,原因就是hash碰撞。这个过程如下图所示:
二、解决上面遇到的问题
依照上面的方案,我们发现布隆过滤器有这些特点:
- 如果判断不存在,那么这个元素一定不存在
- 如果判断存在,那么这个元素可能存在
- 元素不支持删除操作
同样我们上面的方案还是不完美的,不符合生产级,会遇到以下的问题:
- 1.数组到底要申请多大?
- 2.数组满了(所有位置都为1)怎么办?
- 3.如何处理hash碰撞导致的误判
这三个问题相关之间有关联。比如解决第3个问题就要有两个前提,一是数组足够大,二是hash计算出来的值要比较分散。所以顺带要解决第一个问题,数组到底要多大?还有hash函数算法怎么写?
布隆过滤器本质上还是一个容器,用来盛放数据,那么器就算很大还是得考虑到底要放多少东西进去。盛放数据的多寡是决定数组大小的关键。
处理hash碰撞导致误判这个问题可以使用更优的hash算法,第二可以使用多个hash算法来计算一个值然后修改数组中的值来避免hash碰撞带来的误判问题。
既然是容器,那么总会存在满的一天,到时候所有的值经过hash计算都能在过滤器中找到落点,那么布隆过滤器就失去了意义,数组在一开始申请后就确定了大小,需要对数组进行扩容,那么就需要对原来元素进行重新计算下标,但是这个数组不像Java中的HashMap那样记录key值然后重新计算后移动元素。所以我认为原生布隆过滤器不支持扩容(或者叫做伸缩)。
三、实现
首先来解决实现方法问题,最后到底是用什么语言,什么技术去实现都是细枝末节的东西了,所以对于布隆过滤器的需求可以简单的描述为:
我想存放n个元素到布隆过滤器中,并且我希望误判率在p,那么我去实现的时候,我的数组大小要多大?我要经过几次hash计算?
ok,这就变成了一个数学题。
// TODO 数学证明过程
3.1.Redis实现
3.2.Guava实现
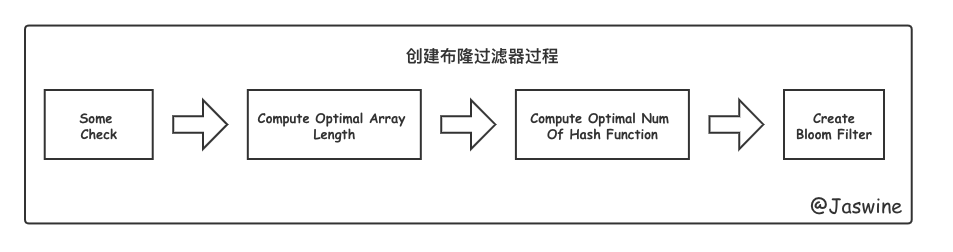
3.2.1.创建布隆过滤器
Guava创建布隆过滤器的过程如下图,其中最重要的两步就是 计算数组的最佳长度 和 计算最佳的Hash函数个数。
$$ length = - \frac{n•ln p} {(ln 2)^2}. $$
其中:
n : 预计盛放元素个数
p : 期望误判率
$$ num = \frac{m • ln 2} {n}. $$
其中:
m : 数组的长度
n : 预计盛放元素个数
其中数组的实现就是一个Long的数组,这个数组是线程安全的,实现的原理就是Java中的原子类(本质就是CAS)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| static final class LockFreeBitArray {
private static final int LONG_ADDRESSABLE_BITS = 6;
final AtomicLongArray data;
private final LongAddable bitCount;
LockFreeBitArray(long bits) {
checkArgument(bits > 0, "data length is zero!");
// Avoid delegating to this(long[]), since AtomicLongArray(long[]) will clone its input and
// thus double memory usage.
this.data =
new AtomicLongArray(Ints.checkedCast(LongMath.divide(bits, 64, RoundingMode.CEILING)));
this.bitCount = LongAddables.create();
}
// 省略了方法
}
|
3.2.2. put元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| /**
* 添加元素到布隆过滤器中
*
* @param object 元素
* @param funnel 转换器
* @param numHashFunctions hash函数的个数
* @param bits 数组
* @return boolean 是否put成功
*/
public <T extends @Nullable Object> boolean put(T object,Funnel<? super T> funnel,int numHashFunctions,LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
|
3.2.3.判断元素是否存在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| /**
* 判断元素是否存在
*
* @param object 元素
* @param funnel 转换器
* @param numHashFunctions hash函数个数
* @param bits 数组
* @return boolean 是否存在
*/
@Override
public <T extends @Nullable Object> boolean mightContain(
@ParametricNullness T object,
Funnel<? super T> funnel,
int numHashFunctions,
LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
if (!bits.get((combinedHash & Long.MAX_VALUE) % bitSize)) {
return false;
}
combinedHash += hash2;
}
return true;
}
|
// TODO
参考
